aX+Y. It is a perfect target for classical
optimizations like partial loop unrolling and scalar promotion -- as
well as clever assembly hacking. (AXPY
is also embarrassingly parallel; however, we focus here on
single-thread performance.) These optimizations are indeed carried
out -- by hand -- in OpenBLAS, regarded as one of the fastest BLAS
implementations. One can make a case for automatic code generation, to
reduce the tedium of applying such optimizations -- given that there are
many platforms and several AXPY varieties to optimize.
This is the traditional elevator talk about metaprogramming in high-performance computing. It is not wrong. There is truth to it -- but not in the place one would have expected.
Magnus Myreen. Quoted by permission.``This make me think that the authors are under the impression that compilers can magically transform bad code into efficient high-quality code by clever enough optimizations. As a compiler writer, I consider this a complete myth that many students and non-compiler-developers hope is a truth. I agree that compilers should aim to improve the efficiency of the code given as input, but one cannot expect the compiler to recognize algorithms and swap them for ones with better asymptotic complexity or make other major code transformations that really should be the job of the programmer. [emphasis mine]''
The present article is an example of making such major transformations: conveniently, modularly, and ensuring at least that the generated code always compiles.
On the example of Basic Linear Algebra (BLAS) we demonstrate modular and correct to some degree code generation and code generators. We start from the obviously correct, algebraic specification of an operation on vectors and apply a sequence of transformations. The transformations are particular enumerations of vector index spaces, often written by combining earlier enumerations. An abstraction -- Linear Memory Address Descriptor (LMAD) -- turns out helpful. The type system of the host language enforces abstractions. The generated code is therefore by very construction well-formed and well-typed, and hence compiles without errors or warnings -- which is particularly important as we explore various optimization opportunities and generate many candidate kernels.
This dry summary hides many surprises and the complete failure along the way.
α X + YBLAS itself is the collection of vector/matrix operations distilled from a large body of numeric code, and which are targeted for aggressive optimizations. The motivation was: rather than spending time optimizing each particular numeric code, it's better to focus on optimizing BLAS.
The fact the AXPY name is short and in uppercase hints at its origin in FORTRAN-II mainframe days.
The precise specification -- or, the reference implementation -- is the following short and straightforward C code:
void AXPY(const int N, const FLOAT da,
const FLOAT x[], const int inc_x, FLOAT y[], const int inc_y){
for(int i=0; i<N; i++)
y[i*inc_y] += da * x[i*inc_x];
}
It includes the stride, or increment, inc to access each vector.
Therefore AXPY can be used to add matrix columns or matrix
rows, or to add a vector to the matrix diagonal, etc. The reference
implementation is taken from OpenBLAS, which is in turn taken from
NetLib, which is (was) the reference for all things numeric.
The reason to distill BLAS is to pour effort into optimizing it. The most optimized BLAS implementations are Intel's MKL, and OpenBLAS (as well as vendor CUDA libraries). Both are optimized by hand. As the name suggests, OpenBLAS is open-source, so we can look at its code (see below). BLAS contains four variations of AXPY: SAXPY (32-bit float vectors), DAXPY (64-bit float), CAXPY (64-bit complex) and ZAXPY (128-bit complex). In the following, we concentrate on DAXPY.
The OpenBLAS DAXPY code for the x86_64 platform is 123-line long (not
counting the kernels) -- quite longer than the 5-liner naive
(reference) C code above. It has two distinct parts -- one for the
case when both inc_x and inc_y are one; the other being the
general case. For the unitary strides, OpenBLAS DAXPY iterates
8-element kernels, which are
#if defined(NEHALEM)
#include "daxpy_microk_nehalem-2.c"
#elif defined(BULLDOZER)
#include "daxpy_microk_bulldozer-2.c"
#elif defined(STEAMROLLER) || defined(EXCAVATOR)
#include "daxpy_microk_steamroller-2.c"
#elif defined(PILEDRIVER)
#include "daxpy_microk_piledriver-2.c"
#elif defined(HASWELL) || defined(ZEN)
#include "daxpy_microk_haswell-2.c"
#elif defined (SKYLAKEX) || defined (COOPERLAKE) || defined (SAPPHIRERAPIDS)
#include "daxpy_microk_skylakex-2.c"
#elif defined(SANDYBRIDGE)
#include "daxpy_microk_sandy-2.c"
#endif
That is, for each particular x86_64 (micro) architecture OpenBLAS includes
a hand-written kernel -- written either using intrinsics, or inline
assembly.
The general case of OpenBLAS DAXPY is the following. (Only the main loop is shown.)
BLASLONG n1 = n & -4;
while(i < n1)
{
FLOAT m1 = da * x[ix] ;
FLOAT m2 = da * x[ix+inc_x] ;
FLOAT m3 = da * x[ix+2*inc_x] ;
FLOAT m4 = da * x[ix+3*inc_x] ;
y[iy] += m1 ;
y[iy+inc_y] += m2 ;
y[iy+2*inc_y] += m3 ;
y[iy+3*inc_y] += m4 ;
ix += inc_x*4 ;
iy += inc_y*4 ;
i+=4 ;
}
The code shows the common HPC pattern of partial loop unrolling and scalar promotion, aimed to hide memory latency. Since reading from main memory takes a lot of time, modern CPUs can do something else in the meanwhile (e.g., decoding and executing further instructions). We take advantage of this facility and arrange four reads from memory (followed by the multiplication upon completion) to run effectively in parallel. Why four, rather than 5 or 8? The optimal factor is determined by the CPU microarchitecture, bus and memory bandwidth and latency, cache organization, memory controllers, access predictors, etc. The many parameters (most of which are not disclosed) make computing the optimal unrolling factor impossible. What one may do instead is to try various unrolling factors and see which leads to a faster code. Such empirical search, or tuning, is very common in HPC. The premise is the ability to produce candidates, with various unrolling factors. Does it sound like fun to write and repeatedly re-write such code by hand (while worrying about typos)?
Besides DAXPY, there is also SAXPY, CAXPY and ZAXPY -- each generally requiring its own tuning, and definitely its own kernels, for each supported microarchitecture. When Intel or AMD introduce a new microarchitecture, which happens every 2-3 years, someone has to write a new kernel, for all AXPYs.
daxpy_openblas.c [4K]
DAXPY code from OpenBLAS (version 0.3.25.dev)
daxpy_microk_haswell-2.c [4K]
Hand-written OpenBLAS DAXPY kernel for the Haswell microarchitecture,
using the vector fused-multiply-accumulate (fmadd) instruction
How does it correspond to real life, in this day and age?
Here is the reality check, comparing the most naive 5-line DAXPY
implementation (the reference implementation, shown above) with the
most sophisticated: OpenBLAS. The benchmark (whose full code is
available below) uses the vectors X and Y of 200,000,000 elements each:
that is, it allocates 3.2 GiB memory. The size of the vectors is
fixed for each benchmark run; what varies is the stride, inc_x and
inc_y.
The platform is Intel Core i5-1135G7 @ 2.40GHz: x86_64 SKYLAKEX
microarchitecture, which provides SSE4, AVX2, AVX512VL, FMA3
instruction sets. The main memory is 8GB with 2 channels, 8
byte/cycle/channel, for the total memory bandwidth 38.4 10^9
bytes/sec. Each core has 128 KiB of 8-way set-associative L1 data
cache and 5 MiB 4-way set-associative L2 cache. There is also 8 MiB
16-way set-associative L3 cache shared by all cores. Cache line size
is 64 bytes (that is, it fits eight 64-bit floats).
The compiler is GCC 11.2.0. OpenBLAS was compiled
for single-thread execution (USE_THREAD=0)
with the
following flags (chosen by the OpenBLAS configuration script)
-O2 -m64 -fPIC -DVERSION="0.3.25.dev" -msse3 -mssse3 -msse4.1 -mavx -mavx2
-march=skylake-avx512 -mavx2
The reference and other code is compiled with the flags
-O3 -m64 -march=native -fno-trapping-math -fomit-frame-pointerThe benchmark is to run only on the target platform; hence I can afford to specify
-march=native: optimize for the target. On the
other hand,
OpenBLAS is meant to be portable to some extent, and cannot afford this
flag (which is a bit unfair to it).
When running benchmarks one has to be always aware that the CPU frequency may dynamically change, from half of the nominal frequency (due to power management) up to twice of the nominal frequency (thanks to Intel's `turbo boost'). Therefore, the benchmark was pinned (to CPU 4) with turbo boost disabled. The benchmark output has confirmed the process remained on the single CPU that kept running at 2390.5 ± 0.5 MHz. The reported execution time is the median of 5 consecutive runs. Thanks to the pinning and the disabling of turbo boost, consecutive runs have nearly identical timings.
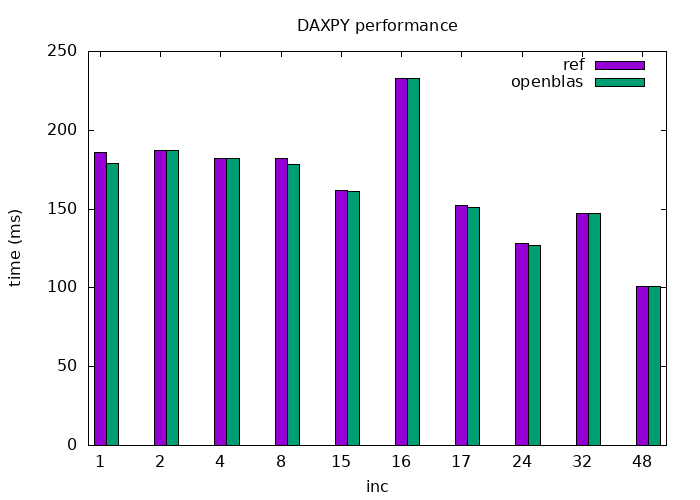
ref_openblas.png [14K]
The benchmark results
There results are quite surprising:
inc=1, the GCC-optimized
code performs nearly the same as the
hand-written OpenBLAS kernels.
inc
increases (recall, the array size is kept constant), the running
time is roughly flat.
inc=16 -- and a less pronounced one
inc=32.
axpy.tar.gz [7K]
The complete code for the benchmark. You can run it on your own
computer and see the results. To run the OpenBLAS benchmark, install
OpenBLAS and adjust openblas_Makefile.
<https://www.kernel.org/doc/Documentation/cpu-freq/boost.txt>
Explanation of the turbo boost and the ways to disable it on Linux.
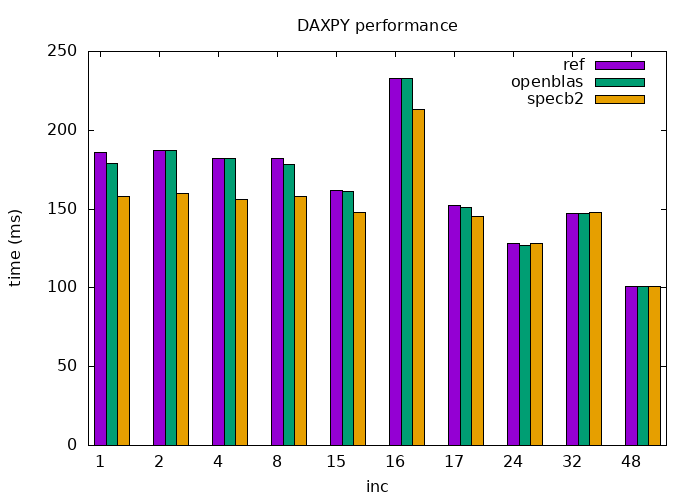
Let's look at the following graph, which adds one more benchmark
specb2 to the earlier reference and OpenBLAS code.
ref_openblas_specb2.png [15K]
One more benchmark result
Especially notable is the case of the unit increment, where specb2
slightly outperforms the hand-optimized OpenBLAS kernels.
Recall, the platform's memory bandwidth is
38.4 10^9
bytes/sec. Each iteration of DAXPY reads 2*8 bytes and writes 8 bytes.
The X and Y arrays have 2 10^8 elements. The bandwidth attained by
specb2 is hence
24*2 10^8 / 0.157 = 30.6 10^9 bytes/sec, or 80% of the memory bandwidth.
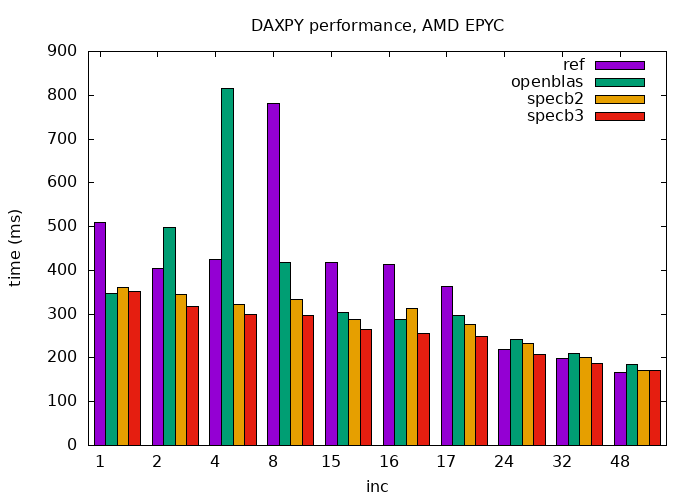
The results are not a fluke. Here is another graph:
ref_openblas_specb23_amd.png [19K]
The target this time is
AMD EPYC 7742 64-Core Processor (Zen-2) server.
Its nominal CPU
frequency is a bit lower (2.2 GHz), but everything else is much bigger:
4 MiB of L1 data, 64 MiB of L2 and 512 MiB of L3 cache, with
128-byte cache lines. The anomalies become quite more pronounced. Our
specb2 (and a bit improved specb3) code manage to avoid them, however.
It turns out, one can improve both on the optimizing C compiler, and
the hand-written kernels and optimizations of OpenBLAS. One look at the
specb2 AXPY code linked below tells it is not written by hand. The
rest of this page shows how it was obtained.
For C generation, we use the tagless-final embedding of C in OCaml, as explained elsewhere. It gives assuredly well-formed and well-typed C code. (With a different back-end, we can also obtain FORTRAN or Wasm code.) But using C, even as an embedded DSL, is too low-level.
Looking a bit ahead, the key is an abstract, general and shorter specification of AXPY:
fun a x y -> vec_map (mul a) x |> iter_assign yIt is a clear, obviously correct specification, with just the right amount of detail. It is also an implementation, given particular realizations of
iter_assign, vec_map and mul. Different choices of these
combinators give different programs: for 32- or 64-bit floating-point
or complex numbers, different loop unrollings.
The code specb2 was obtained via a particular choice of iter_assign -- a
particular sequence
of executing array reads and writes. Let us illustrate.specb2 code
Tagless-final
embedding of (a subset of) C in OCaml
The code-generation framework
module type RING = sig
type t (* abstract *)
val zero : t
val one : t
val add : t -> t -> t
val sub : t -> t -> t
val mul : t -> t -> t
end
which can be turned into the type
type α ring = (module RING with type t = α)The combinator
mul mentioned earlier is hence a RING operation.
Vectors may be generically defined as so-called `pull vectors': a mapping from a range of indices of type ι to values (of type α):
type (ι,α) vec = Vec of ι lmads * (* index space description *)
(ι -> α)
where ι lmads, the list of ι lmad
(short for linear memory address description -- the
description of the index space) is presented in the next section.
The type t of vector elements is
typically the type of ring values -- for a vector over a ring.
It may also be a function type τ -> ω, which signifies an
`update', or `consumption' of a value of type τ.
The type ω represents an update (action), which has to be a monoid:
updates may be composed. Thus a generic output vector is defined as
type (ι,α,ω) ovec = (ι,α->ω) vec
The generic vectors let us define generic operations on them, such as
vec_map : (α -> β) -> (ι,α) vec -> (ι,β) vec and
zip_with f v1 v2 -- applying a binary operation f to
vectors v1 and v2 elementwise:
let zip_with : (α -> β -> γ) -> (ι,α) vec -> (ι,β) vec -> (ι,γ) vec =
fun tf (Vec (n1,f1)) (Vec (n2,f2)) ->
assert( n1 == n2 );
Vec (n1, fun i -> tf (f1 i) (f2 i))
The LMADs of the two vector operands must be physically equal.
(If they were not, one should have reconciled them first: convert the
two vectors to the common index space.)
On the other hand, the operation iter_assign
to assign an input vector to an output vector
is not generic. It is ι,ω-specific.
One may think of it as the reduction over the monoid ω.
type (ι,α,ω) iter_assign = (ι, α, ω) ovec -> (ι, α) vec -> ωIt is in turn expressed, one way or another, via
iter, which embodies a particular way of
enumerating the index space (and hence of executing
vector updates -- element assignments).
type (ι,ω) iter = ι lmad -> (ι -> ω) -> ωThe particular instances of
iter_assign or iter (for specific
ι, ω) are described later below.
One such common expression for iter_assign in terms of iter is
let iter_assign : (ι,ω) iter -> (ω list -> ω) -> (ι,α,ω) iter_assign =
fun iter seq ->
fun vout v -> zip_with (@@) vout v |> function Vec (lmads,body) ->
List.map (fun l -> iter l body) lmads |> seq
where the second argument is the reduction over the ω monoid.
AXPY on the generic vectors can then be written as
let daxpy (type a) ((module R):a ring) (iter_assign : (ι,a,ω) iter_assign) =
fun a x y -> vec_map (R.mul a) x |> iter_assign y
as we said in the previous section. This is the general,
textbook code, which we write once and for all.
After that, we instantiate it in various ways, as below.
LMAD generally is a set of primitive LMADs, each of which is written
in the following notation
As₁s₂...u₁u₂... + b
Here
b is the base offset, sd is the stride, or step, along
the dimension d, and ud is the exclusive upper bound along
the dimension d.
Informally, a primitive LMAD as above represents a for-loop nest:
for(i=0; i < u₁; i += s₁)
for(j=0; j < u₂; j += s₂)
...
point in index space b+i+j+...
A set of primitive LMADs then represents a sequence of nested
for-loops.
In OCaml, LMAD is realized as the following data type:
type ι lmad = {offset: ι;
extent: ι ext list}
and ι ext = {
upb: ι; (* that is, greater than max index *)
step: ι (* also stride, or scale *)
}
and ι lmads = ι lmad list
The meaning of LMAD -- as an enumeration of the index space, or the
list of indices -- is then given by the following OCaml code.
let iota : int lmad -> int list = function {offset;extent} ->
let rec extents = function
| [] -> []
| [{upb;step}] ->
let rec loop i = if i >= upb then [] else i :: loop (i+step) in
loop 0
| ext::exts -> (* Cartesian product *)
let ext_space = extents [ext] in
extents exts |> List.concat_map (fun i -> List.map ((+) i) ext_space)
in
extents extent |> List.map ((+) offset)
This denotation lets us distill LMAD laws, which are used later in
generation of the fast AXPY code. (I have not yet checked if these
laws are mentioned in the LMAD literature.) More constructively, the
meaning function iota can be used to spot-check the laws: compute the
denotation of the left- and right-hand--side of a concrete instance of
the law, and see if they match. The accompanying OCaml code does
exactly that to verify the laws.
0 < ks <= u and k is a natural number.
(The case ks = u is trivial.)
≍
A...s₂...s₁......u₂...u₁... + b
≍ means equivalence up to the traversal order. The two LMADs
represent different traversals, but of the same index space. The law
follows from the commutativity of addition (or, in other words, from
the absence of dependencies among the loops).
u is divisible by k and k is divisible by s. This law
represents the optimizations known as strip-mining:
stripping a loop into a
number of consecutive blocks (of statically known size k/s).
This effectively turns the loop into two nested ones: the outer
over blocks, and the inner over elements within a block.
Algebraically, it turns a (u/s) column vector into
a matrix of u/k rows and k/s columns.
J. Hoeflinger. Interprocedural Parallelization Using Memory Classification Analysis. PhD thesis, University of Illinois at Urbana-Champaign, July 1998.
Jiajing Zhu, Jay P. Hoeflinger, David A. Padua.
Compiling for a Hybrid Programming Model Using the LMAD Representation.
Languages and Compilers for Parallel Computing, 2001 (LNCS 2624)
The paper is not about LMAD per se: it is about compiling for a
cluster. LMAD is merely a tool -- very cleverly used. It is introduced
there rather concisely.
axpy.ml [43K]
The code accompanying the article. Search for LMAD.
C_cde, abbreviated to just C. Integer expressions of the C
language are represented in OCaml as values of the type int C.exp,
and similarly for bool and other expressions.
Statements of C are represented by values of
the type τ C.stm, where τ is often unit (which corresponds to
void in C); unit C.stm is a monoid, with the reduction
seq : unit C.stm list -> unit C.stm -- meaning that C statements can
be combined into one composite statement.
There are several realizations of the RING: For example,
floating-point numbers, to a good approximation:
module RingFloat = struct
type t = float
let zero = 0.
let one = 1.
let add = Stdlib.( +. )
let sub = Stdlib.( -. )
let mul = Stdlib.( *. )
end
The ring element type is OCaml float, with
add being the OCaml float addition, etc.
Code of floats is also a RING:
module RingFloatCode = struct
open C
type t = float exp
let zero = float 0.
let one = float 1.
let add = ( +. )
let sub = ( -. )
let mul = ( *. )
end
The elements of RingFloatCode have the type float C.exp:
expressions of the target language of float type (which corresponds
to double in C.) The ring product generates the multiplication code.
It is easy to write RING implementation for single-precision
(32-bit) floating-point numbers, and for variously represented complex
numbers.
To instantiate the daxpy code generator we also need iter, the
enumerator of the index space. The earlier iota immediately gives
one iterator:
let iter_sta : (int, unit C.stm) iter = fun lmad body ->
iota lmad |> List.map body |> seq
which corresponds to full loop unrolling. If the loop bounds are not
statically known (i.e., are of the type int C.exp rather than int), we
generate for-loops. (Here >> is the left-to-right functional composition.)
let iter_dyn : (int C.exp,unit C.stm) iter = fun {offset;extent} body ->
let rec extents body = function
| [] -> seq []
| [{upb;step}] -> C.(for_ (int 0) ?step:(Some step) (upb-int 1) body)
| ext::exts ->
extents (fun i -> extents (C.(+) i >> body) exts) [ext]
in extents (C.(+) offset >> body) extent
The full code also defines the iterator for the hybrid case, when
the loop bounds may be statically known. If they are and the
number of iterations is small, the loop is unrolled.
Given the Ring and iter, we can instantiate the daxpy generator
(repeated from above)
let daxpy (type a) ((module R):a ring) (iter_assign : (ι,a,ω) iter_assign) =
fun a x y -> vec_map (R.mul a) x |> iter_assign y
and produce the AXPY code. For example,
daxpy (module RingFloatCode) (iter_assign iter_dyn seq) results in
void daxpy(int const n_8,double const a_9,double * const x_10,
int const inc_x_11,double * const y_12,int const inc_y_13){
for (int i_14 = 0; i_14 < n_8; i_14 += 1)
array1_incr(y_12,i_14 * inc_y_13,a_9 * (x_10[i_14 * inc_x_11]));
}
where
#define array1_incr(a,i,v) a[i] += vThis is the reference AXPY implementation.
Applying algebraic laws to the LMAD describing the
input arrays results in a more complicated (but correct by
construction!) C code. The specb2 code is the result of applying
the horizontal split, two vertical splits and interchange laws, with the
particular choice of parameters (strip size).
c_cde.ml [8K]
Embedded target language (the implementation of the cde signature)
And yet, one may still obtain AXPY that performs better than what an
optimizing C compiler or a BLAS library may deliver -- using
appropriate abstraction and code generation. The code specb2
described here is just one example. I cannot claim it is the best:
perhaps one can do even better. The code generation has many tunable
parameters, whose space is yet to be explored. There is much work
ahead.
{kind=link}
{kind=link}
{kind=link}